


Summary
We’re working hard on the impending 0.0.3 Developer Preview Release! It will contain all the things we’ve talked about since 0.0.2, plus a few new developer-facing improvements. This week’s Pulse is focused on better debug logging, successful multi-agent scenario testing, and the difference between addresses and hashes.
Highlights
- Better Debug Logging: Configurable, colorful output to delight developers
- Faster build and testing cycle for developers equals greater productivity
- More Reliable Multi-agent Scenario Testing
- DNA Now has an Address on the DHT: Preparation for App Store
- Additional Improvements: Easier Developer Experience
- Holochain 101: Addresses, hashes, and a cloud of data
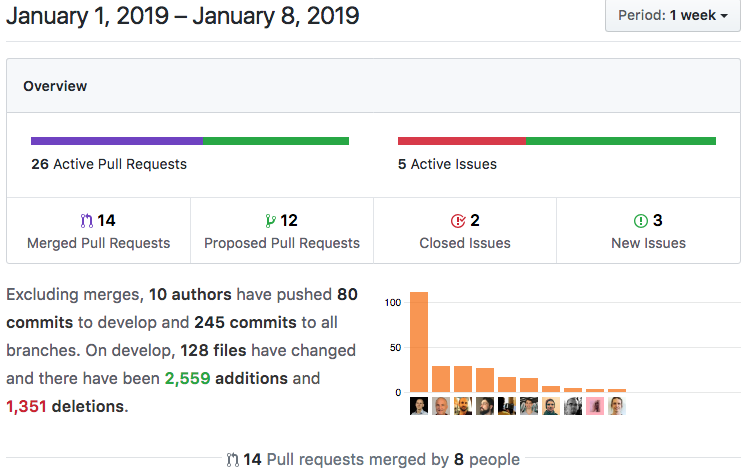
Details
1. Better Debug Logging: Configurable, colorful output to delight developers
While we build Holochain, we’re also building some key internal Holochain apps (hApps). These are core hApps, such as DPKI and HoloVault, a team productivity hApp called Abundance of Presence, and of course, all the hApps that will power the Holo hosting network. We’re also receiving early feedback from DevCamp participants and active developers from the Holoverse. All of this feedback is pushing us to sharpen the developer experience rapidly.
We’ve heard you say you want better debugging/logging output, so we’re continuing to improve it! Expect to be able to configure logging channels per hApp instance0.
The stderr channel is useful enough, but we’re working on a channel that loops back to the container. This will do really exciting things like colorizing the output per-instance and filtering by message type or arbitrary regex.
2. Faster build and testing cycle for developers equals greater productivity
Developers using our Docker image for development may have found that build times are slow. We’ve made some improvements to Rust incremental builds, so you should see
a 5× speedup on the initial build, as well as some speed improvements when you’re building your hApp’s DNA.

3. More Reliable Multi-agent Scenario Testing
We talked about the pain of running multi-agent scenario tests in NodeJS in last week’s Pulse. These are the tests for checking back-and-forth processes such as currency transactions. Just like with a real DHT, agent 2 had to keep checking back to see if they’d received the data that agent 1 had sent. We promised some tools to help you out, and they’re almost ready! Soon, you’ll be able to use a `scenario()` function to run isolated tests that provides functions `callSync()` and `callWithPromise()` (in addition to the usual `call()`). These functions allow you to use Promises to block the test, waiting until all network activity has completed before executing the rest of the test.
4. DNA Now has an Address on the DHT: Preparation for App Store
The DNA, which is the collection of rules, functions, and data structures that make up the core of a hApp, lives on each agent’s device.
Each DNA has its own unique ID (a ‘hash’), which is part of Holochain’s resilience. If you don’t have the right DNA, you can’t produce the right hash, and that means you’re not running the same rules as everyone else. The DNA also lives on the DHT, but until now there was no way to ask the DHT for it by address. This means that you couldn’t create universal links that everyone in the hApp could find, such as a global directory of usernames. Now that DNA is addressable, you can call `link_entries(hdk::api::DNA_ADDRESS, some_other_address, tag)` without throwing an error. Note: This should be used sparingly to avoid excessive burdens on the agents who are responsible for holding those links.
5. Additional Improvements: Easier Developer Experience

Look for these and more improvements in the 0.0.3 Developer Preview — coming soon!
- Option to receive ‘sources’ metadata when asking the DHT for entries or links.
- Option to receive CRUD history and status when asking the DHT for entries.
- Automatically load linked entries with `get_links_and_load()`.
- Return multiple entry types when querying your source chain with glob matching.
6. Holochain 101: Addresses, hashes, and a cloud of data

When we talk about ‘content-addressed storage’ in a ‘distributed hashtable,’ we’re talking about something very different from the way you normally access data. On the traditional web, when you enter an address like http://example.org/pictures/2019/happy-cat.jpeg, your browser asks the example.org server for a happy cat picture in a folder called pictures/2019. This is called location-addressed storage, and it’s fairly easy to understand. You go to a place to look for a thing and that’s where you find it.
{kind=link}
It’s also fairly fragile; if the example.org server goes down, or they rearrange or delete things, you can no longer access that happy cat picture. Content-addressed storage is a solution to this problem.
Instead of asking one machine for a piece of information by name, you ask a network of machines for a piece of information by its unique ‘fingerprint,’ and they talk amongst each other until one of them finds it. These machines store redundant copies of the information, so even if the original machine deletes it, another machine most likely has it.
What is this fingerprint? It’s a large number called a ‘hash,’ which is produced by running the content through the digital equivalent of a meat grinder. It is (nearly) unique for any piece of content that you could produce. Any given piece of content will always have the same hash, and any other piece of content, even if it differs by only one comma or one pixel, will have a wildly different hash. Now that we have this way of reliably assigning a unique ID to a piece of data, we also have a way of giving it an address that remains the same no matter where it actually lives.
In a DHT like Holochain, each machine also gets an address. These addresses are long numbers just like the content addresses, so they can all be compared with one another to find out how close they are. Each machine has a list of ‘peer machines’ that it keeps in touch with regularly. Those peers are mostly in its ‘neighborhood’ — that is, their addresses are similar to its own, like house numbers that increase slowly as you walk up the street.

When you want to store your happy cat picture on the DHT, you create an address by hashing it, then you find the peer whose address is the closest to the picture’s address. You give the picture to that peer for validation and storage. They might respond by saying, “yes, you’ve got it now,” or “sorry, you know someone whose address is even closer; they should be responsible for this picture.”
Searching for a piece of content is similar. Let’s say I’ve given you the address of my happy cat picture to brighten your day. You look at the address, compare it to the addresses of your peers, then talk to the peer whose address is closest to the cat picture’s address. They will either give it to you or refer you to another peer.
As long as you know its unique address and the addresses of your neighbors you can quickly search for any content across a loose network of unreliable computers.
All the address generation and data routing happens at the ‘behind the scene,’ within Holochain itself, so you don’t need to know much about how it works. As a developer, it’s enough to know that agents, content, and even your app’s DNA all have addresses on the DHT. Those addresses can be used as unique IDs for retrieval, linking, and sharing of content and identities.
It’s also important to know that you shouldn’t ever try to create an address yourself by hashing a JSON string or an agent ID, because Holochain has special rules for creating them (not all addresses are hashes).
Instead, ask an agent or content struct for its address by calling its `.address()` method, or get the DNA address via the global constant `hdk::api::DNA_ADDRESS.`