Cover photo by Nicolas Picard on Unsplash
This week we got word that a patent we submitted to the USPTO was approved. That means that Holochain’s special DHT design — rrDHT — is covered under intellectual property laws.
To be honest, when I heard we were filing for a patent, I was surprised and not entirely comfortable with the idea. So let’s get my (and probably your) ethical concerns out of the way first.
Why did we file for a software patent?
The most pressing reason is troll protection. Patent trolls are organisations that sit on large collections of patents simply so they can collect licensing fees from people who actually build things — and sue the ones who don’t buy a license. This is an unfortunate reality that we must face — because we plan to build a revenue-generating business on Holochain tech, we may become an attractive target for trolls. This patent helps protect us — and every business that builds on Holochain.
It also helps make the Cryptographic Autonomy License more enforceable. I don’t pretend to understand the legal artistry that went into all this, but I gather that it gives extra legal teeth to anyone attempting to use the CAL to defend end-users’ data sovereignty and access to the Holochain codebase.
But isn’t Holochain open source? Isn’t this kinda… closed?
The patent isn’t an open patent right now; we still want to figure out appropriate licensing schemes that make sure that it gets used in ways that align with our values. But any application developer who has a license to Holochain (which is anyone) gets to enjoy the use of that patent in their software. And it’s being transferred from Holo (the company) to the Holochain foundation this month.
I’ve got more thoughts about patents, ethics, and living in the current world while trying to create a new world. But I’ll save them for the end of this article. And you can read more about the ‘why’ and the ‘how’, including how to use the patent in your own non-Holochain-based software, in Holo’s press release.
Now, on to the ‘what’!
rrDHT, a relaxed, agent-centric distributed hash table
Background: what is a DHT?
The patent language starts out with some legalese, then breaks into some pretty accessible language before returning to legalese. At the beginning, we learn that...
While it is possible to design computing systems that don't use state, many problems — particularly those that are designed to reflect human interactions and the physical world — are easier to model when the computing system has state.
In computing terms, ‘state’ means ‘remembering things’. It’s what turns computers from simple machines to magical ‘do-everything’ machines.
Consider a weaving loom. It takes in thread and produces cloth. Pretty cool, but pretty simple.
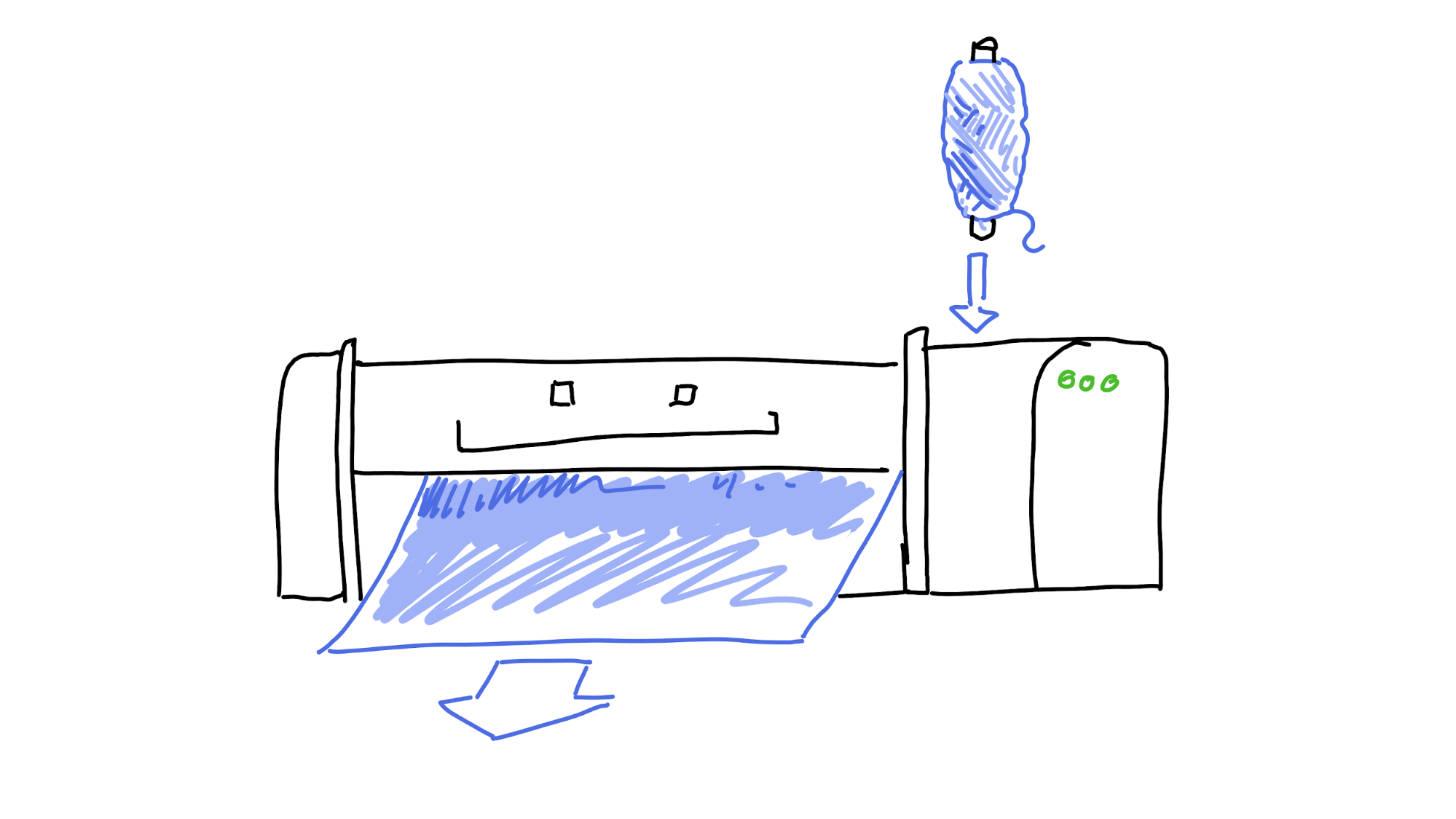
Now let’s add ‘state’, or ‘memory of where I’ve been and where I’m going’ to the loom. Now it can know that it’s done twelve lines of blue and needs to change to yellow, but only once it gets a third of the way through the thirteenth line. Suddenly, it can create something really special.
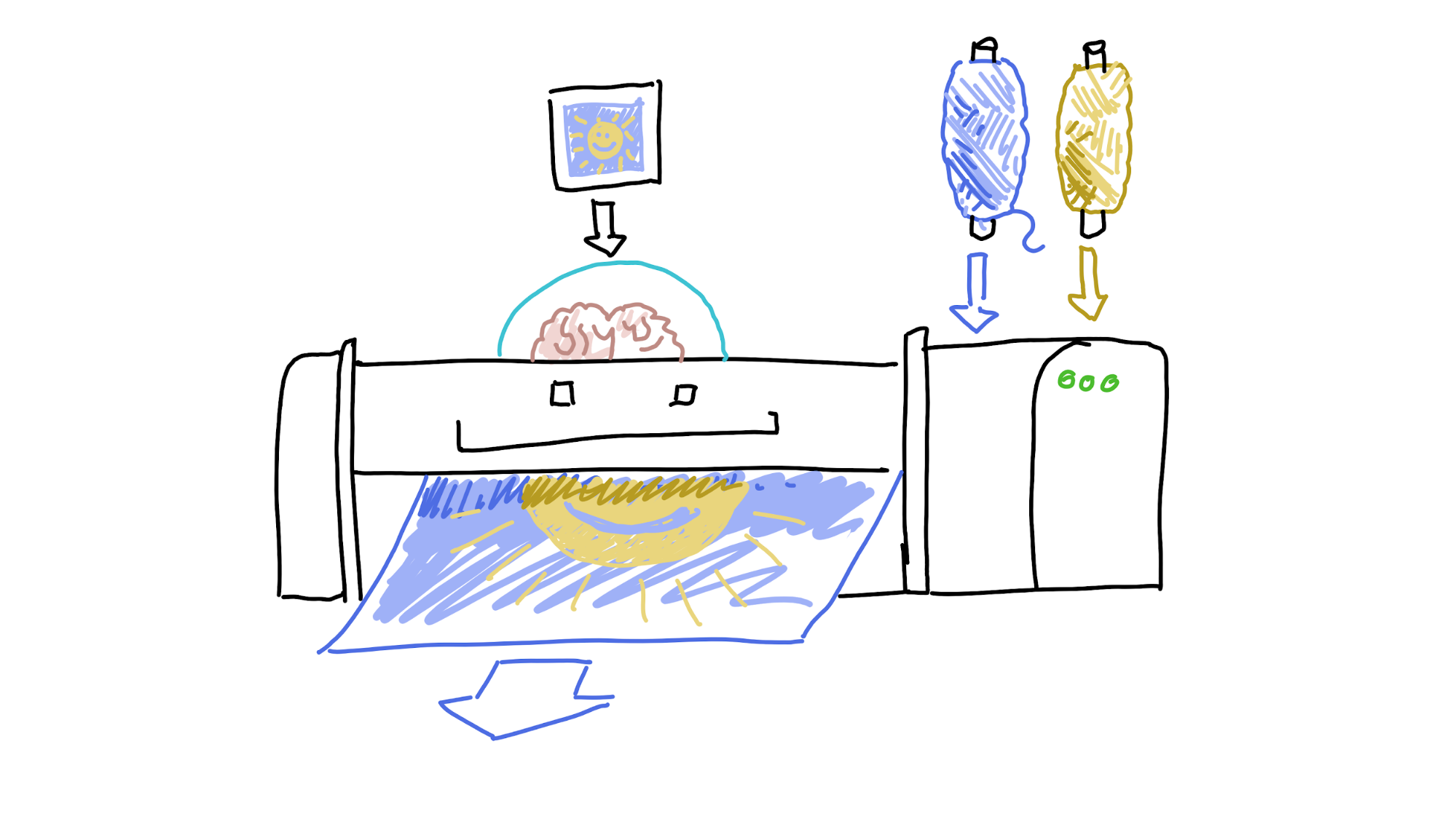
So far, so simple. We know that computers remember stuff. But it gets complicated when you involve more than one computer, because who’s in charge of remembering the state?
Even though we operate in a networked era, most online tools you use operate in a centralised way — client/server — where a central authority takes care of remembering everything.
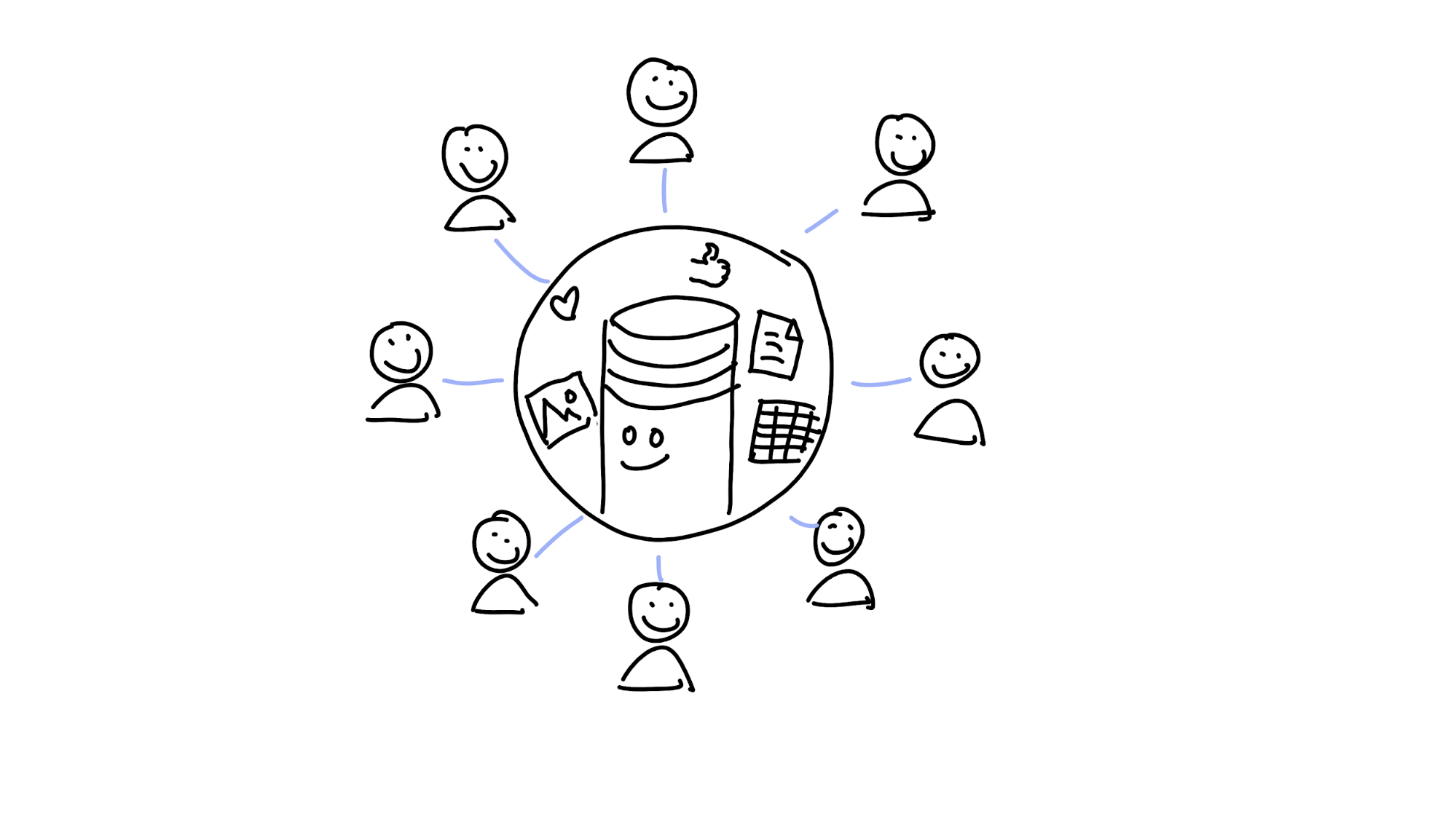
That’s nice and easy, and it works great — until the database shuts down, the company gets bought out or goes out of business, or the system gets co-opted by someone with evil plans.
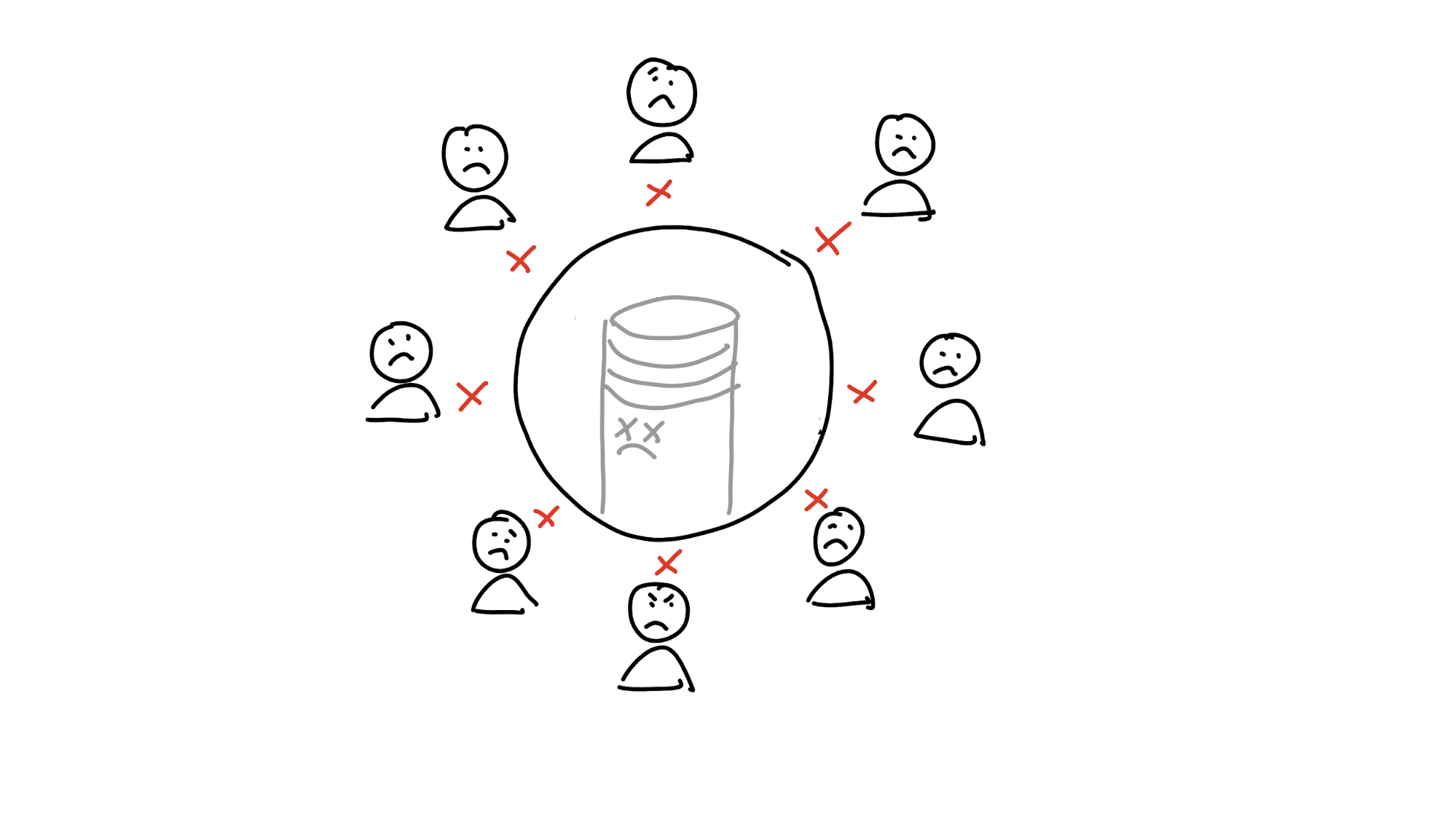
This prompts us to set out to find a better way of holding shared memory — one that isn’t vulnerable to disruptions or bad actors. If you got rid of the central database and distributed the data to all the participants, it would certainly help. But now you’ve got a new problem: without any authority to talk to, how do you find the data you’re looking for?
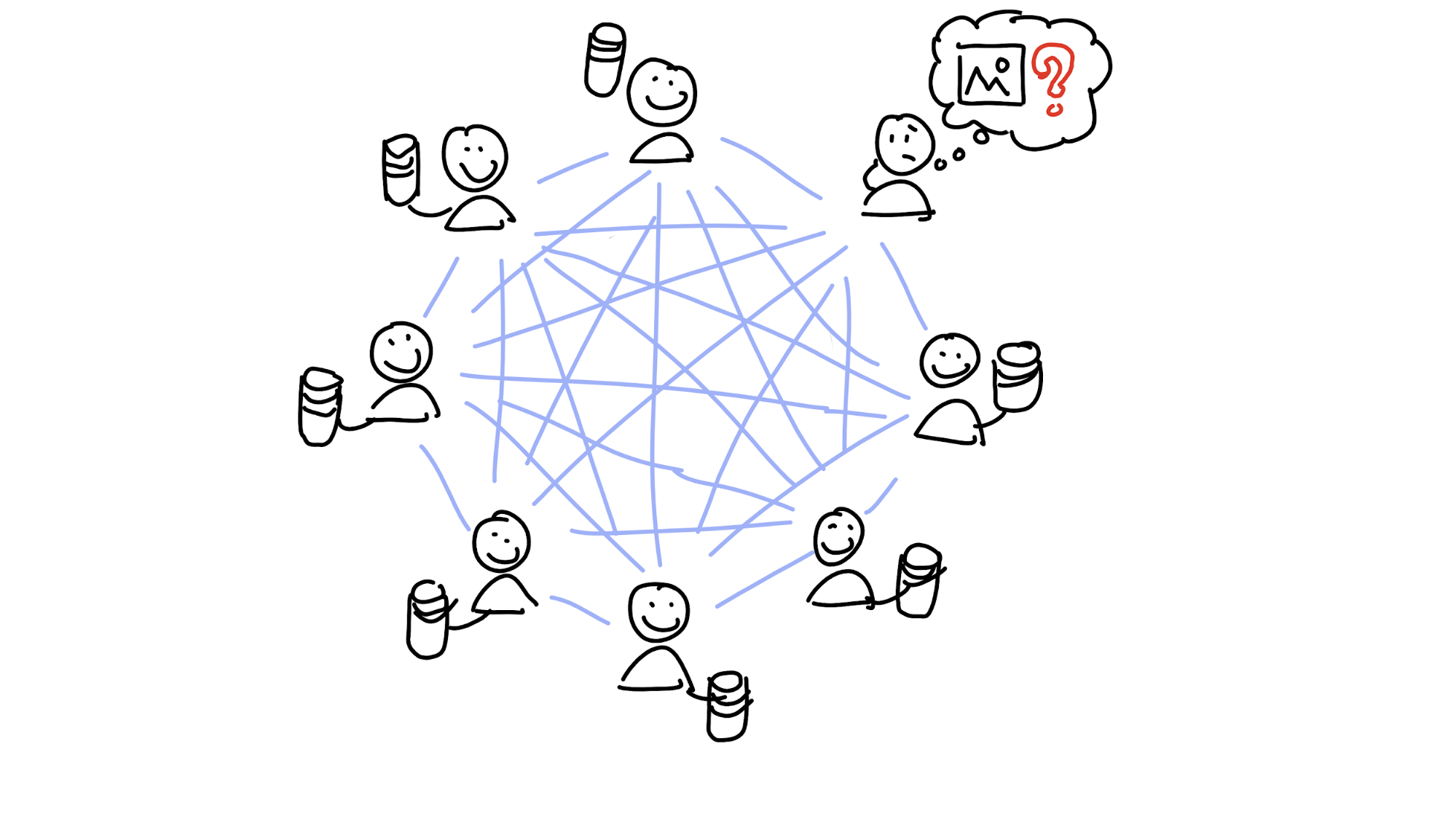
The distributed hash table (DHT) was created to help solve this problem. A hash table is just a simple index of keys (things you know) that point to values (things you want). It’s a bit like a dictionary: when you want to know the definition of the word ‘floccinaucinihilipilification’, you take its name (the key) and search through the book until you find it. On the same line you’ll see the definition (the value associated with the key).

A distributed hash table just spreads responsibility for the keys and values across a lot of machines — each one stores just a portion of them. This means that, if one machine disappears, only a little bit of data is lost.
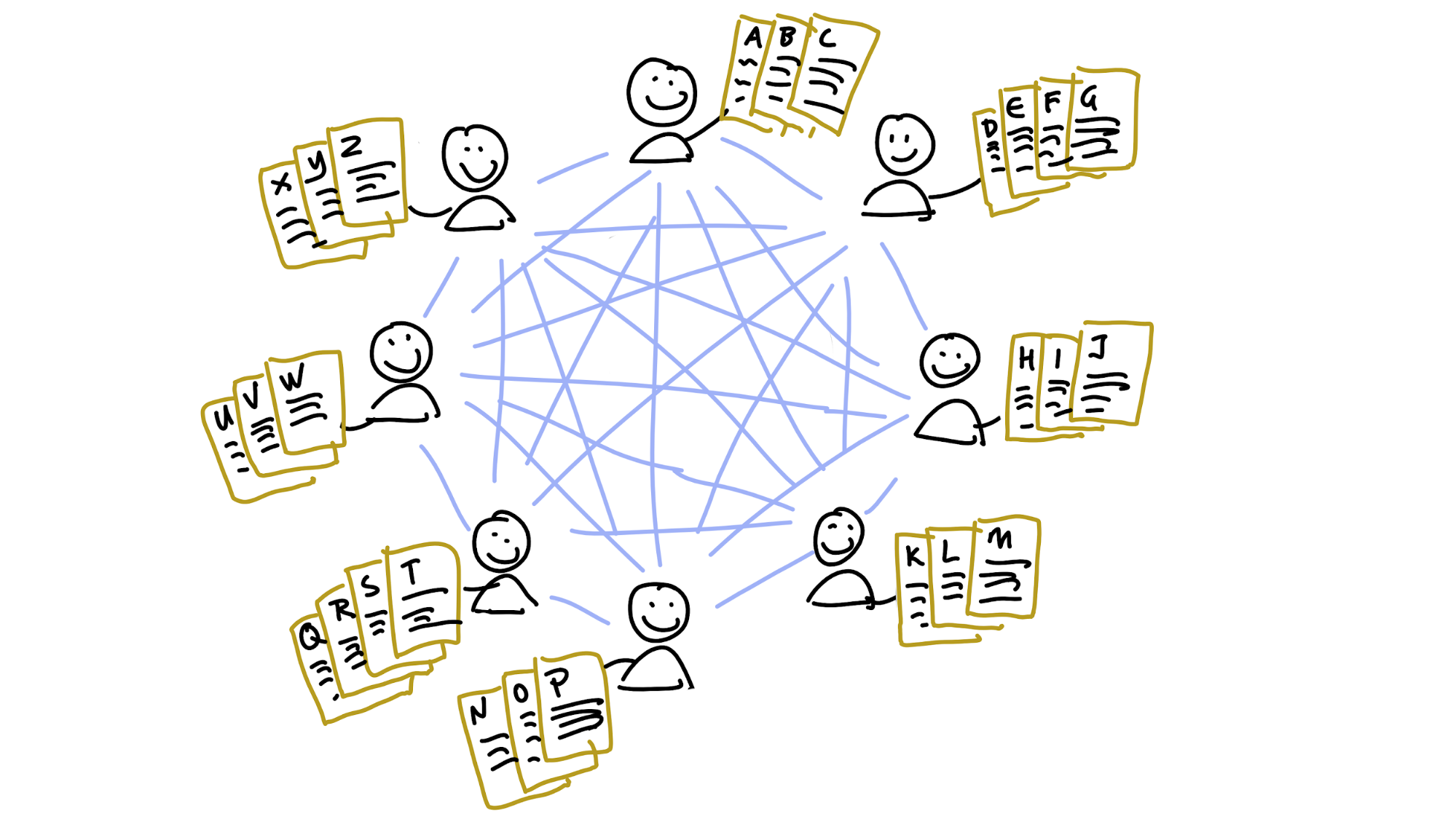
Of course, now if you want to retrieve a piece of data, you have to figure out who’s got it. You don’t want a central index (remember, that’s risky), so instead you need a way of figuring it out on your own. Here’s how it works.
We’ve already seen that every piece of data in a hash table has a key. In a distributed hash table, every machine has a key too.
In order to find the machine that has the data you want, you compare the data’s key against the keys of all the machines you know about, using a “nearness” algorithm, and then ask the closest match for the data at that key. If they don’t have it, it’s likely that they know another nearby machine that does.
Storing data works the same way: you calculate the key for the data you want to store, compare it against the machine keys, and ask the computers whose addresses are nearest the key of the data to store it for you.
Different DHTs use different ways of calculating nearness, and might implement different ways of recovering from failures such as a machine going offline.
How rrDHT makes things fast and robust
rrDHT starts out with a pretty simple nearness algorithm — keys are just 32-bit numbers, and the machine whose number is closest to the data’s number is the best match. This makes lookups very fast to calculate.
We also want to make a Holochain app’s DHT as resilient as possible. Machines come and go, especially when they’re just users’ laptops and phones, and that means that your ‘best match’ for a data key might disappear for weeks at a time. So we want the participants in a DHT to collaborate to make sure each piece of data is stored by more than one responsible party.
So each peer — which in Holochain is both an end-user and a storage machine — has a range of the key space that it considers its ‘neighbourhood’. (You can think of the keys as addresses.)
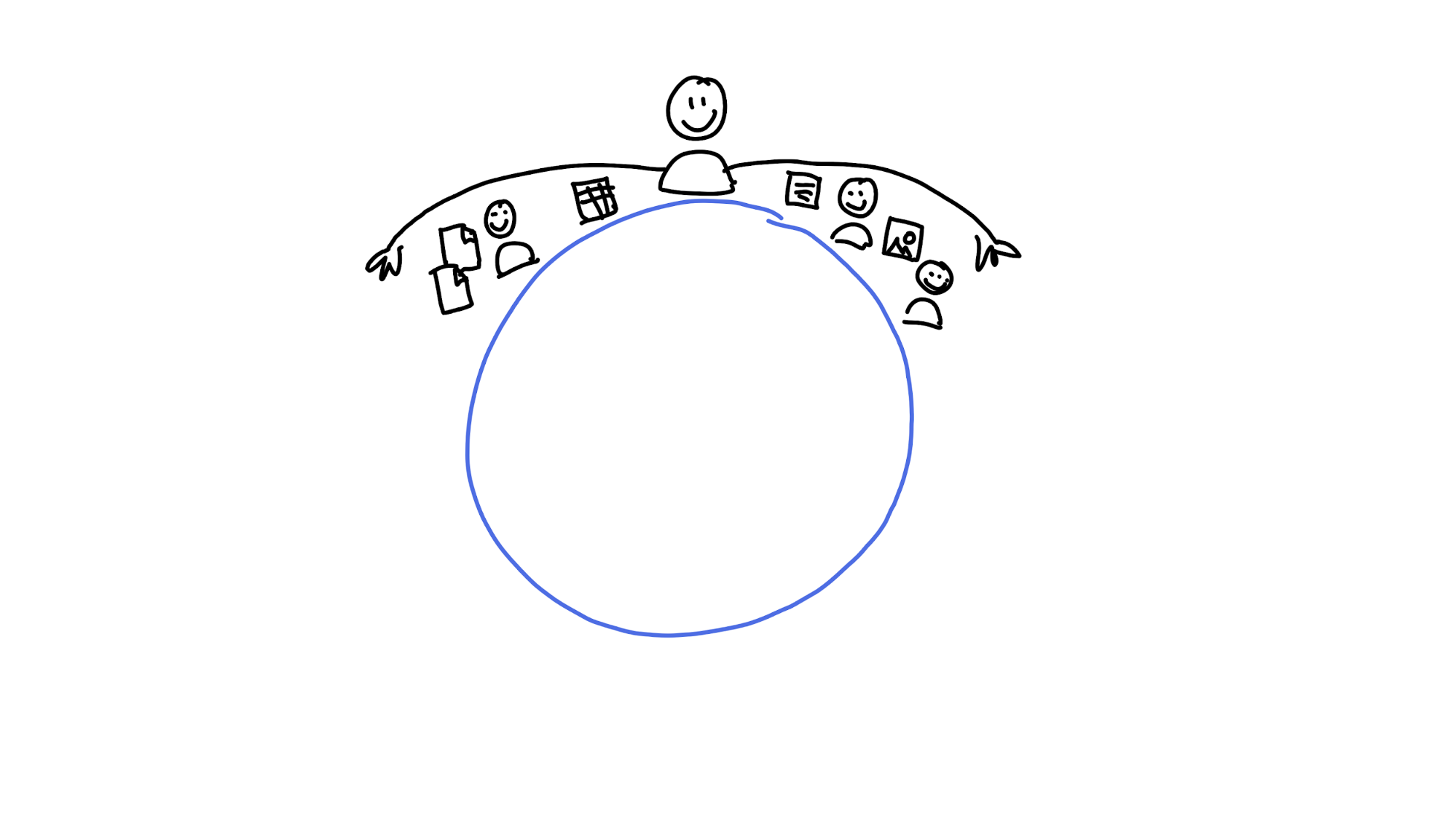
From your place in the DHT, your neighbourhood stretches out to your left and right. Here, you know everybody by name and have a good idea what’s happening in their lives. You take responsibility for storing a copy of all data whose keys fall within it, to the best of your ability. You also know the transport addresses of all peers whose keys fall within it. (A transport address is the address in the underlying networking layer — an IP address, for example. It lets you do the actual communication.) You gossip over the fence regularly, sharing data with each other. If you go offline, your neighbours have your back, because their neighbourhoods overlap with yours and they can ‘heal’ the gap you left behind.
The size of your neighbourhood depends on your capacity and the resilience of your neighbourhood. If you find your device storage is filling up too quickly, rrDHT might choose to shrink your neighbourhood and drop responsibility for some data. And if you notice the coverage just outside your neighbourhood seems a bit weak, rrDHT might enlarge your neighbourhood and help improve resilience there.
Outside of this neighbourhood, you might have a couple connections with reliable peers spread across other regions of the DHT. (The patent suggests between five and ten.)
Neighbourhood lookups in action
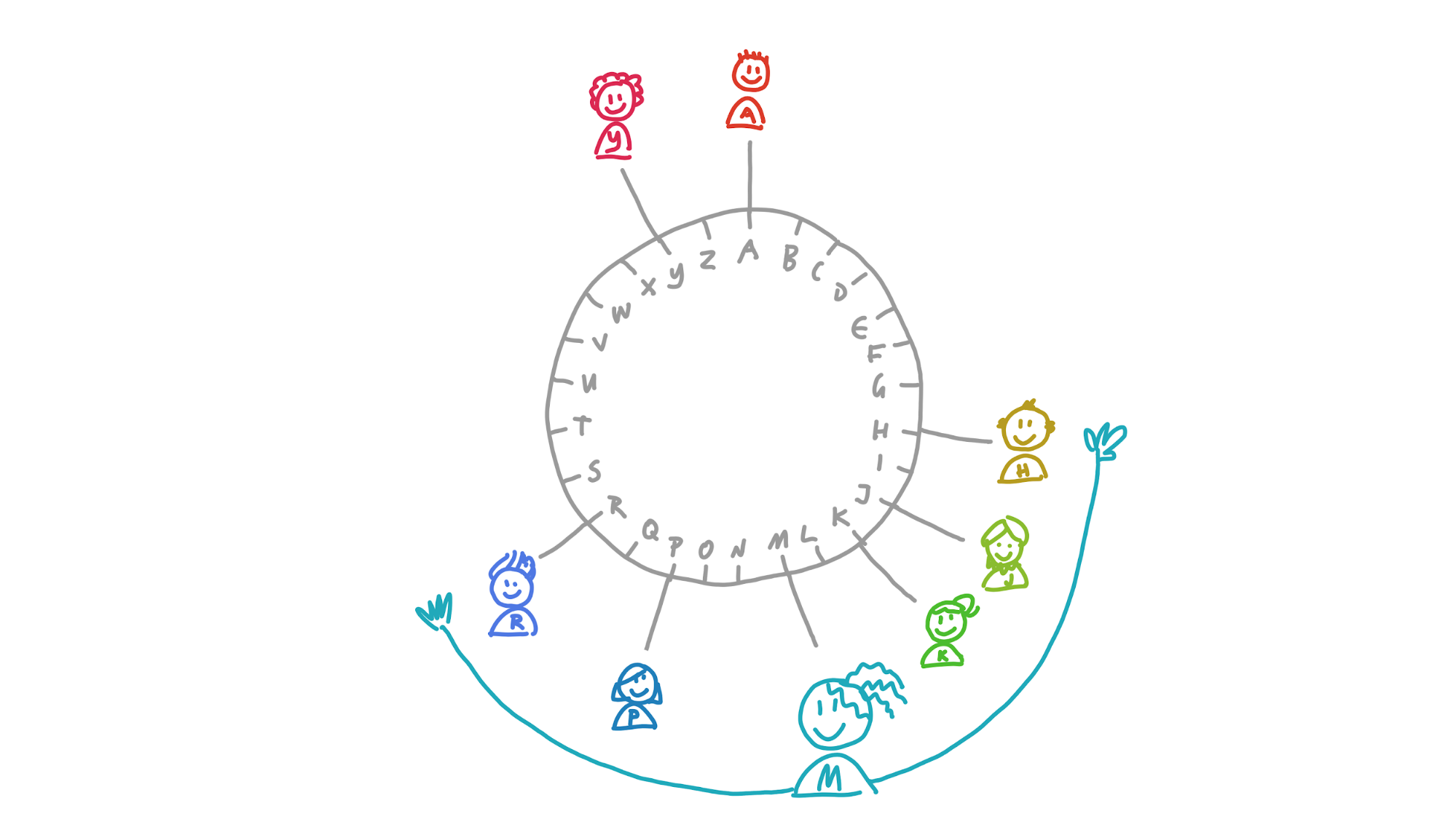
Here’s how data storage and retrieval works in rrDHT. Instead of using numbers, I’ll make things easier and use the letters of the alphabet.
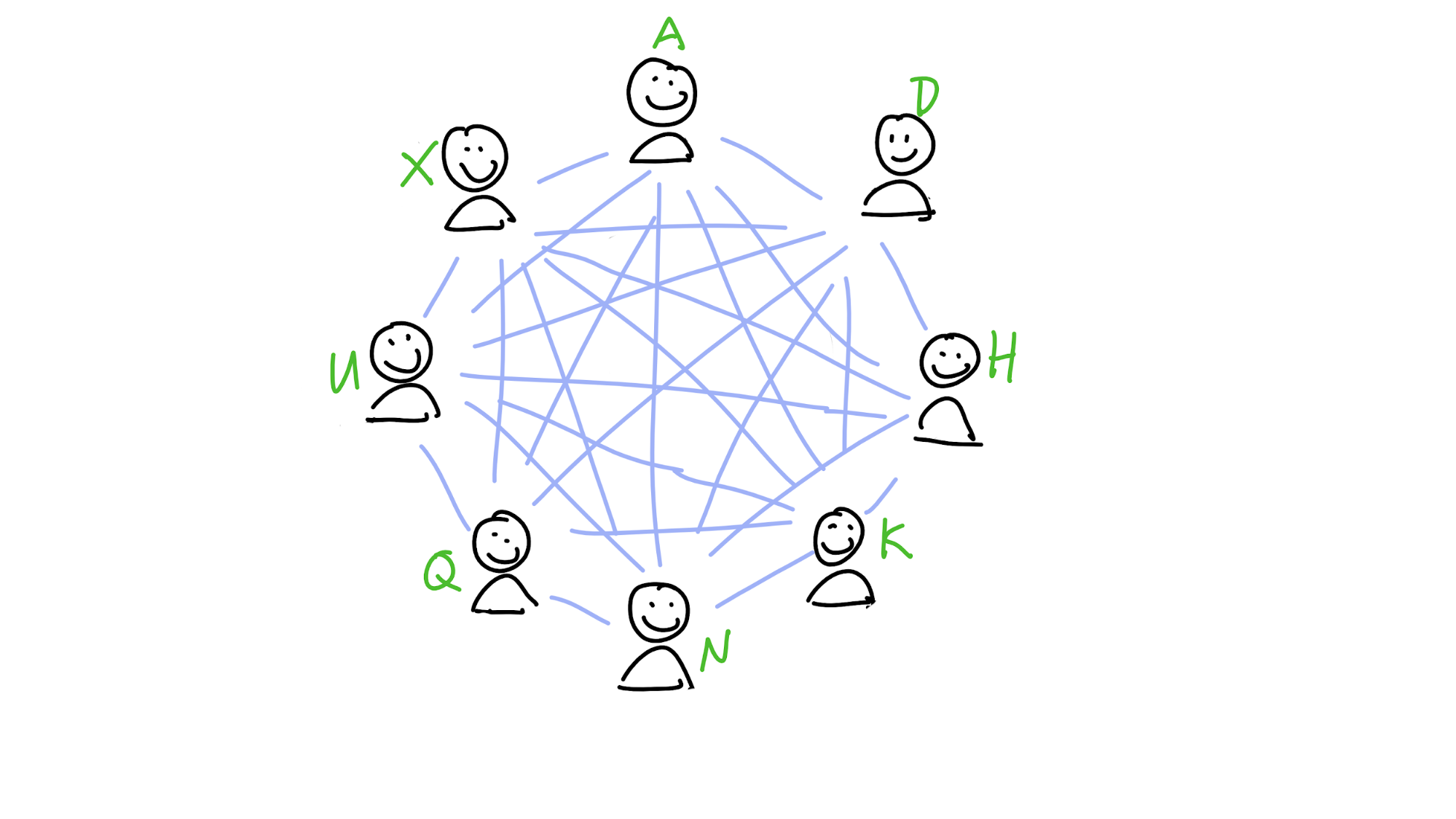
Maria and her friends are members of a dictionary DHT that stores words and their definitions. In the picture below, you can see the DHT from her perspective, with her neighbourhood spreading out from her place in the DHT:
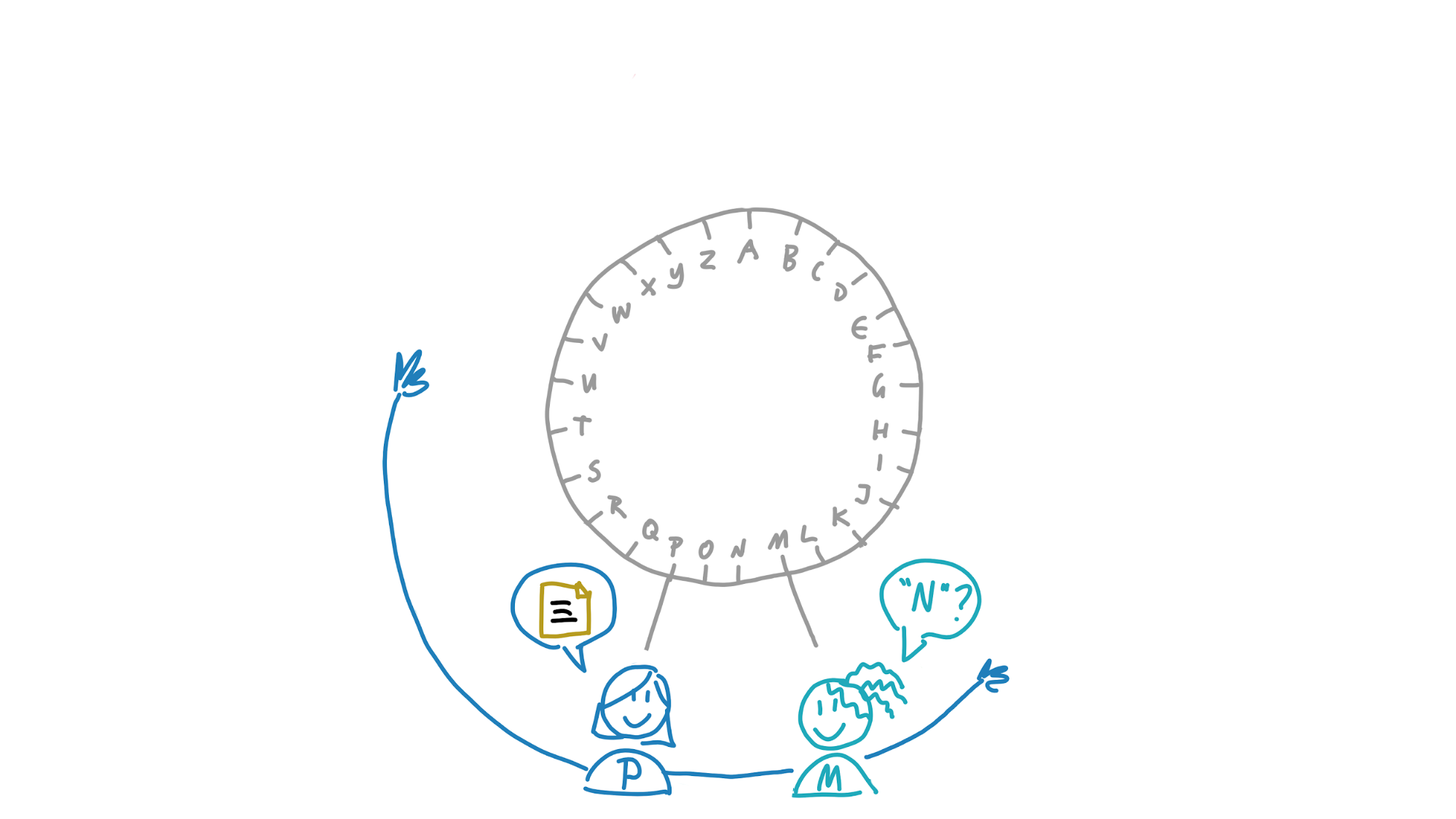
Maria wants to know the meaning of the word ‘nanotechnology’. She calculates its address, which is N. That’s inside her neighbourhood, so she probably already has it in her own storage slice. But if she doesn’t yet, she asks Paulina, whose neighbourhood also covers that address. Paulina returns the definition to her.
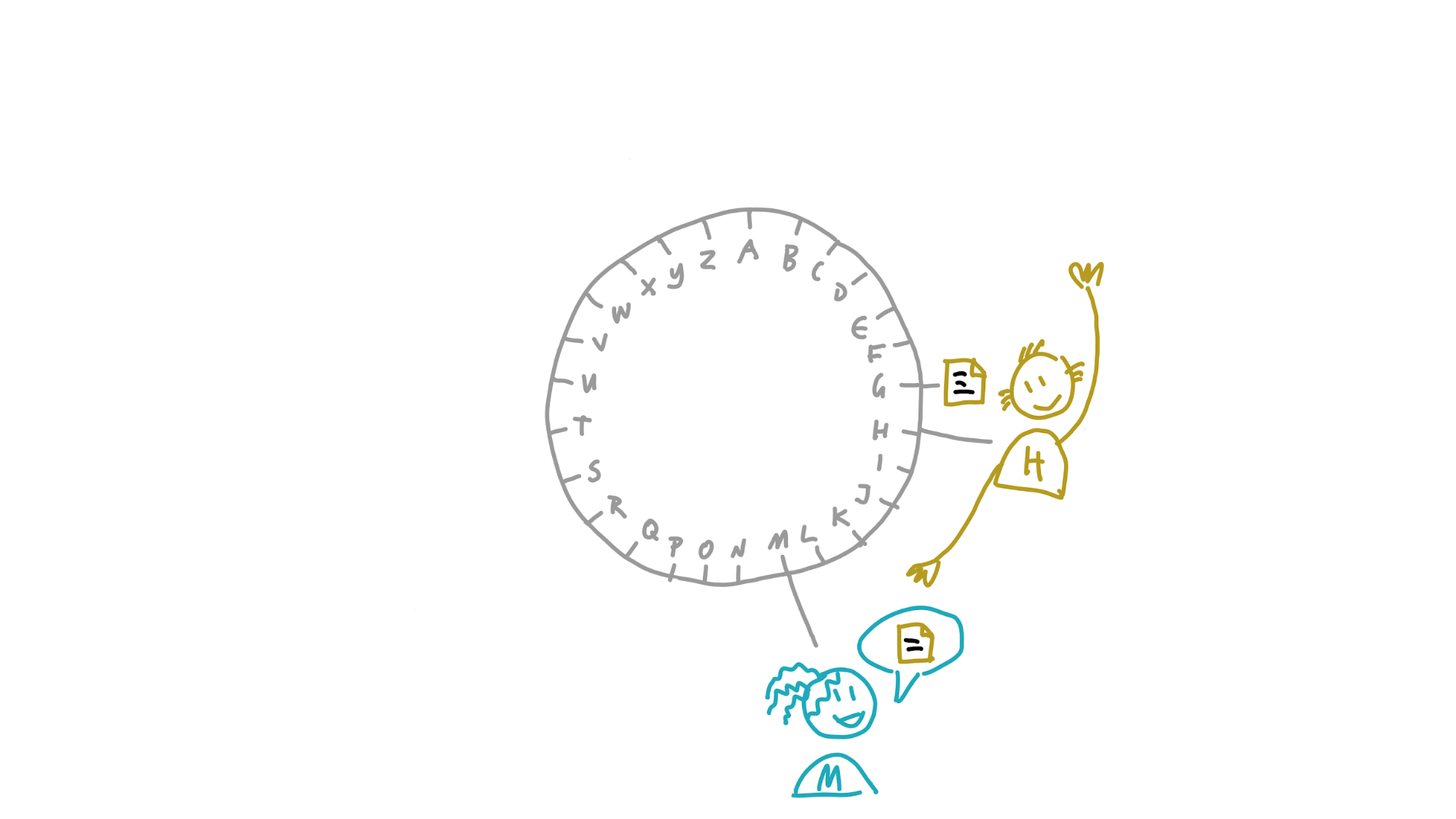
Now she wants to store a definition for the word ‘galangal’. She calculates its address, G. If her neighbourhood were just a bit larger, she’d take responsibility for storing a copy herself and gossiping it to her neighbours. She sees that Henry, however, is really close to it. She sends it to him and, because his neighbourhood covers G, he stores it.
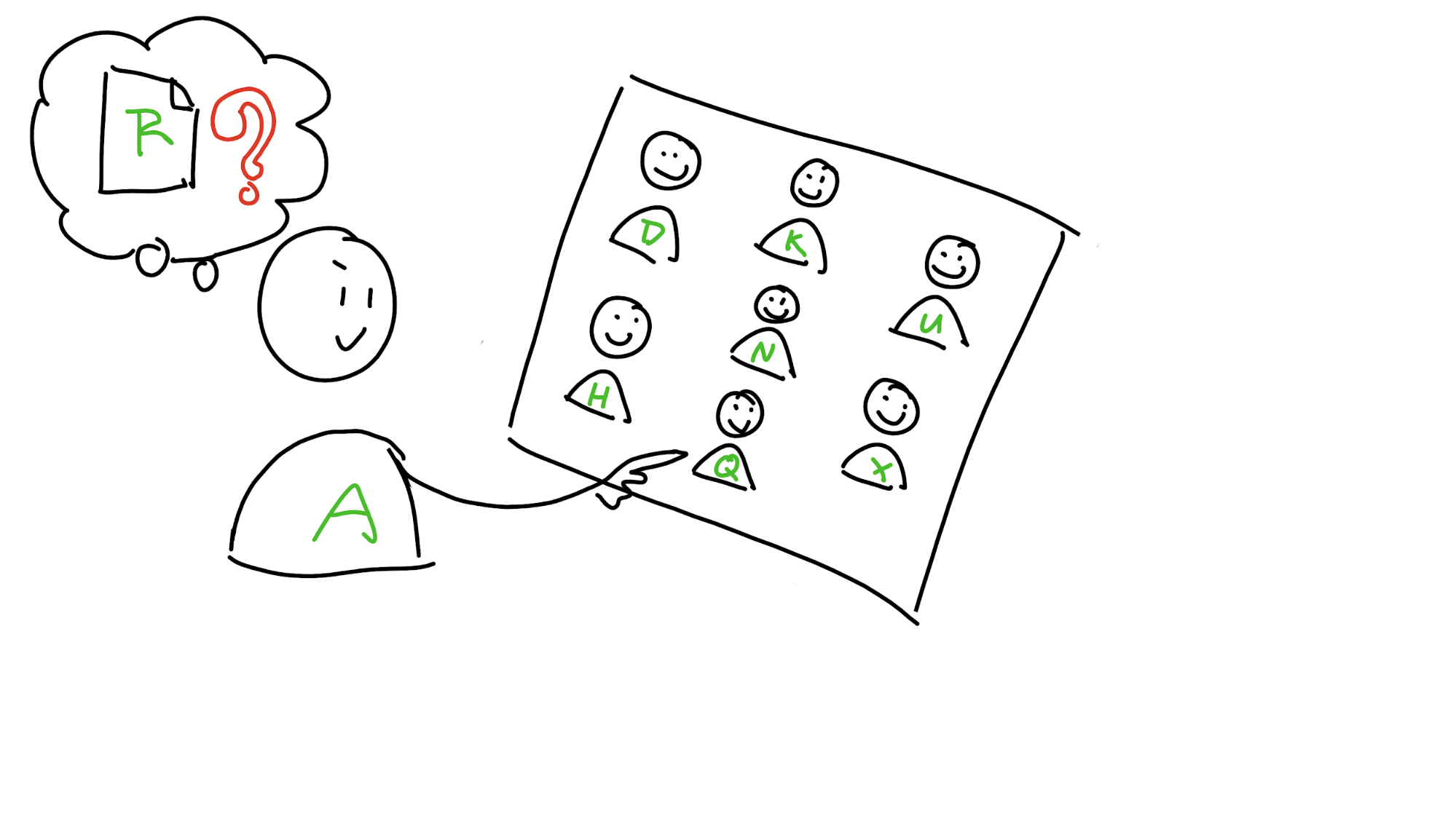
Finally, she wants to know the meaning of ‘caterwaul’. Its address, C, is also outside of her neighbourhood, and she doesn’t know anybody in her neighbourhood who’s close to it. The closest peer she knows about is Aoki. Aoki will have a better view of that part of the DHT than she does, so she asks him for the data. His neighbourhood doesn’t stretch far enough, though, so he doesn’t have it. But within his neighbourhood is Carol, whose neighbourhood does cover it. He sends Carol’s transport address to Maria, who asks Carol for the data.
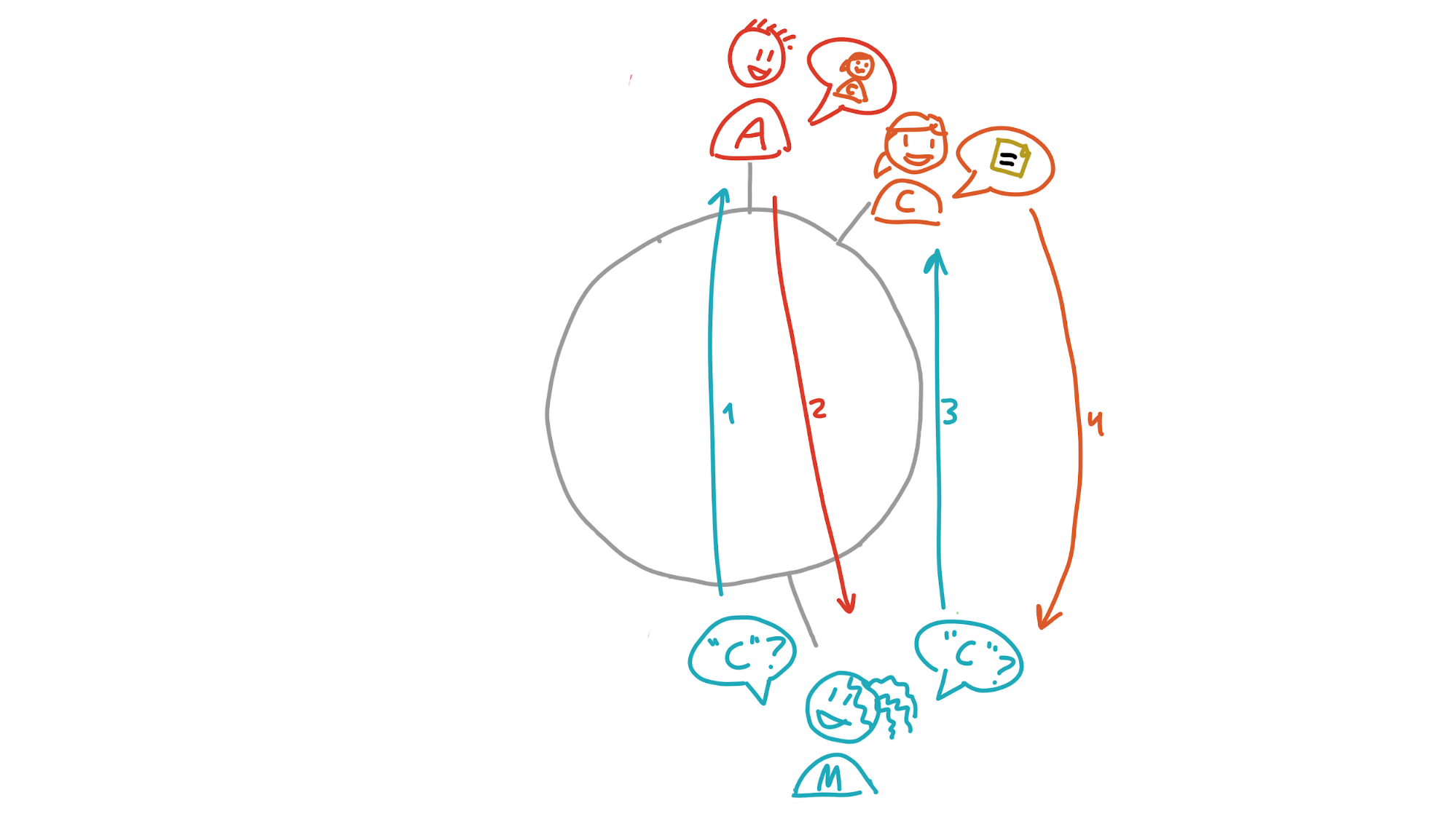
We expect that, with most application DHTs, it’ll only take a few hops to get the data you’re looking for. Even in the worst-case scenario of a DHT with full saturation of the address space (roughly four billion peers who each have a tiny neighbourhood of two addresses in either direction), it’ll only take 22 hops.
(Note: there’s a second, broader neighbourhood that I didn’t mention. Maria doesn’t store data whose addresses fall in this neighbourhood, but she does keep tabs on who lives there. This helps improve resilience and lookup times.)
Why did we build something from scratch?
There are a lot of good DHT designs out there, and the nice thing about them is that they already have implementations we could’ve used. In fact, the first iteration of Holochain used IPFS’ implementation of the Kademlia DHT. And it worked okay for finding data — it was fast and well-supported — but the challenge is that we want Holochain to have self-healing storage where data gets moved to peers with nearby addresses. And it was very hard to describe that kind of neighbourhood with Kademlia's nearness algorithm. And Holochain wasn’t just using neighbourhoods for data storage and retrieval – it was using them for security too.
To understand that, we need to back up a bit and look at another problem that pops up when you take the authority out of the middle.
As I mentioned before, if an application wants to work right, it needs an assurance that it’s got a predictable view of the stored data, or state. If you expect X to equal 3 but it actually equals 7, your application might start throwing errors. But when nobody’s in charge of keeping that state consistent, the individual copies can get out of sync and make a mess of things. So you need to figure out who gets to modify that shared memory, and when. That is, how do you prevent two people from modifying the same thing at the same time on their separate machines? (Remember, there’s no central authority anymore — and there’s a new group of bad guys who would love to get involved too.) This problem was identified back in 1983 as the Byzantine Generals’ Problem.
A common strategy is to select a ‘leader’ — the entity who’s allowed to make writes — and make sure that nobody else can write to the data.
Bitcoin, while not the first to tackle this problem, is certainly a pioneer when it comes to a strategy for leader selection among an unknown number of untrustworthy members. It simplifies the problem by recording everyone’s data writes in a single journal, of which everyone has a copy. Then a lottery is held every 10 minutes to select the next leader. This lottery helps keep everyone honest. But by design it’s expensive to play, in real time and money. This means that those with more money tend to dominate the game. That doesn’t feel very peer-to-peer anymore.
This is necessary because of Bitcoin’s design choice — that single, shared ledger is pretty attractive to bad actors, so it needs to be well protected. But we don’t think a shared ledger is actually necessary for ensuring data integrity.
Holochain makes things even simpler by saying, “why don’t we just put everyone in charge of their own write journal?” That’s where a peer-to-peer application runs anyway — on the devices of its users. This solves the leader selection problem; everyone is their own leader!
That’s fine when you’re just writing data for yourself. But when you start interacting with others, and everyone's in charge of their own data, how do you police bad data? Particularly problematic is the ability to manipulate your own history; you could do all sorts of fun stuff with that. Make negative balances disappear, change your mind about the politician you just voted for, modify things you said in the past without any accountability trail, etc.
Holochain’s answer is to make everyone accountable to everyone else. And here’s where that neighbourhood model comes in: when a neighbourhood is called on to store a piece of someone else’s public data, they first validate it according to Holochain’s #1 rule (you can’t manipulate your journal) and an application’s particular rules. If they find any suspicious activity, they sound the alarm. This alarm acts like an antibody — it spreads through the network of peers, triggering an immune response in each of them until everyone recognises the bad actor and has taken steps to protect themselves. (This usually looks like putting the bad actor in a block list.)
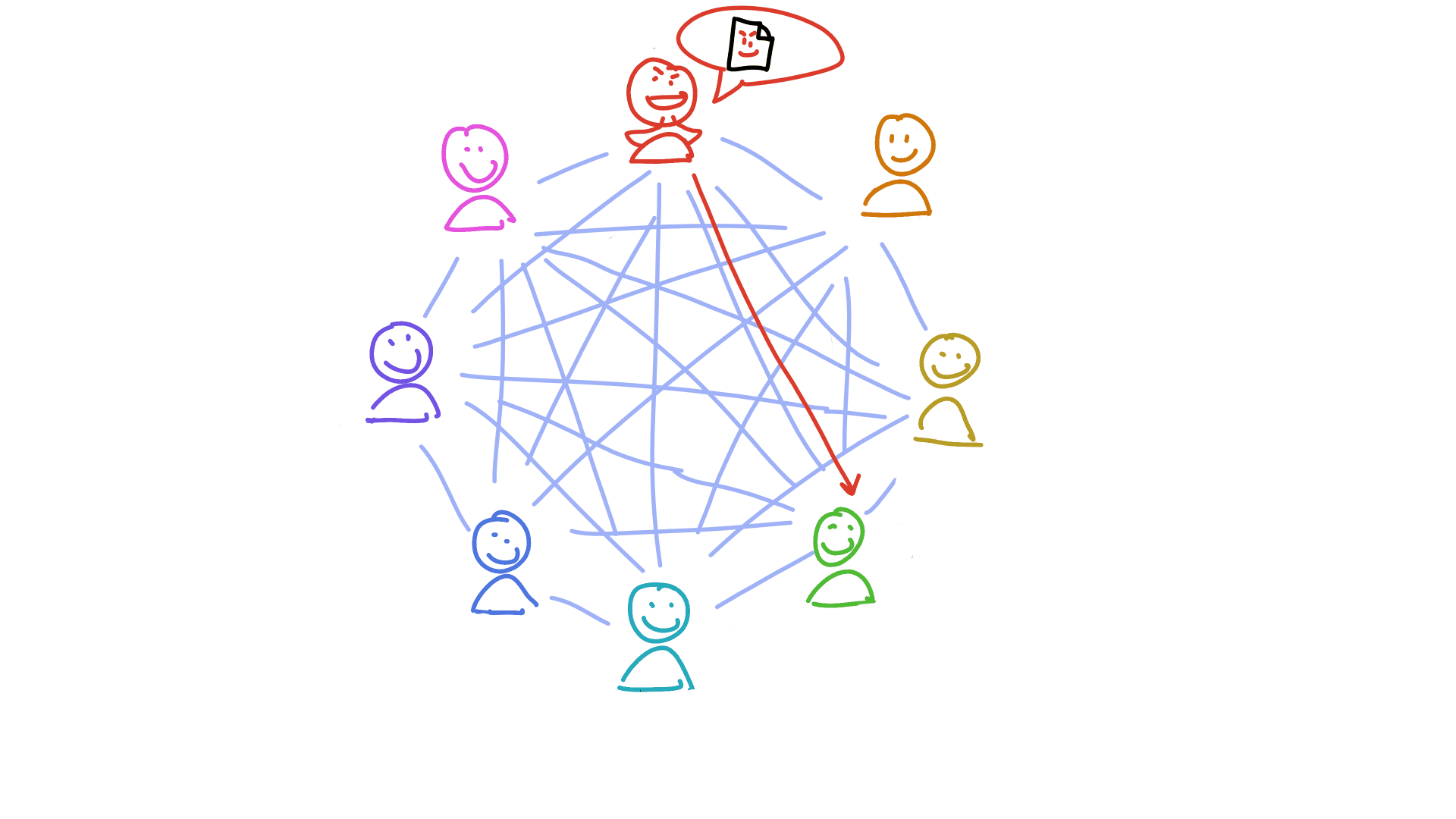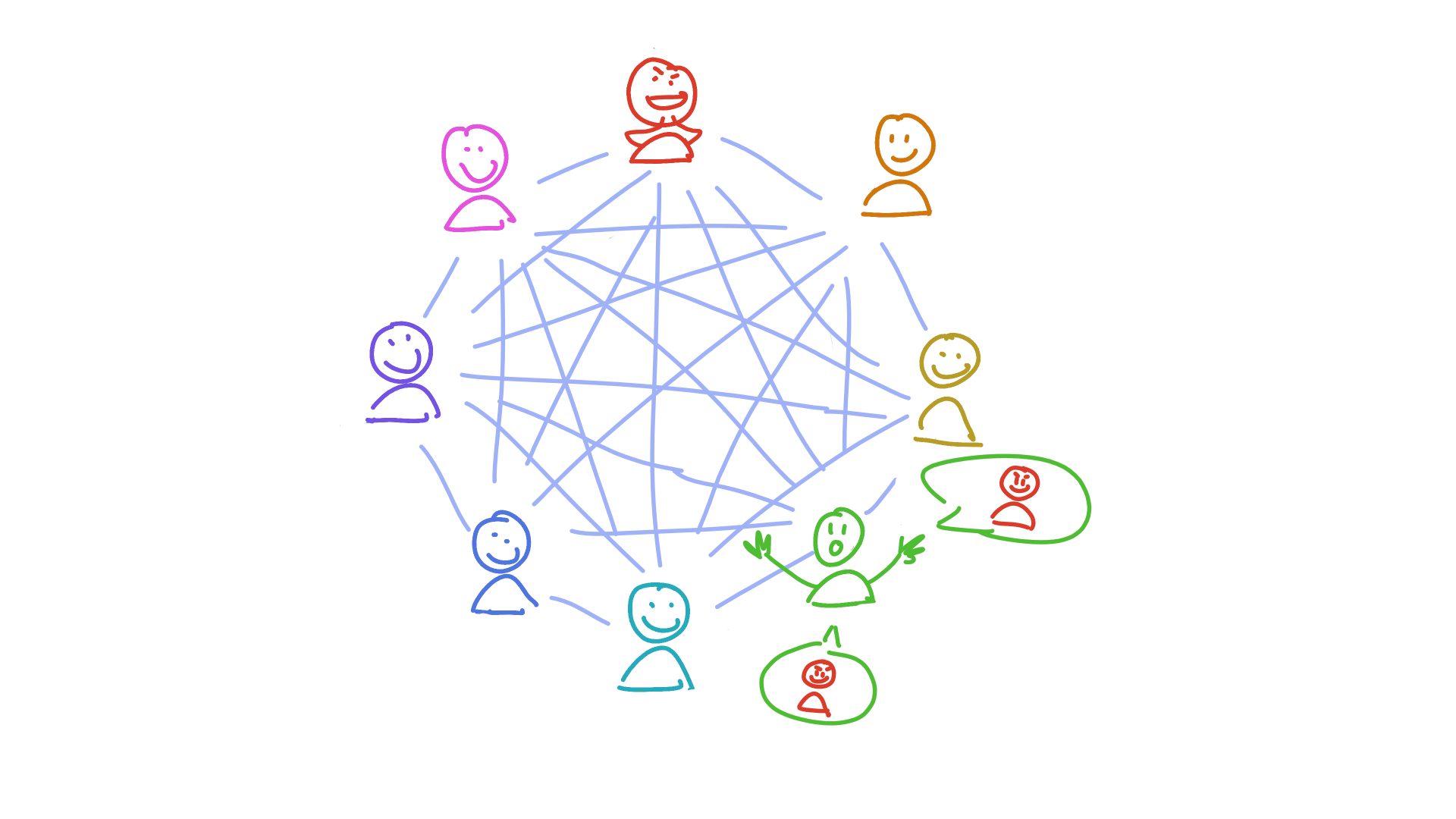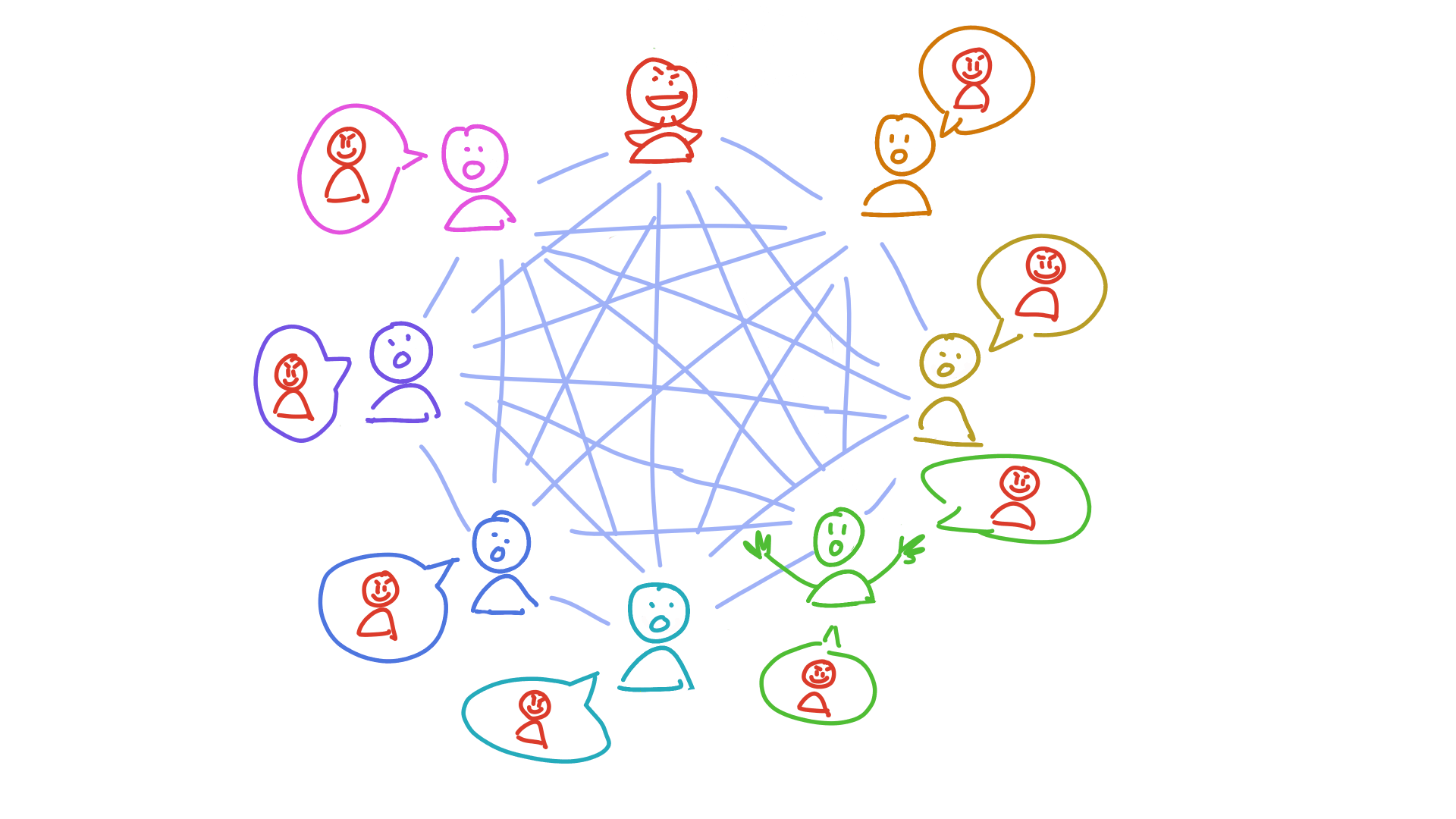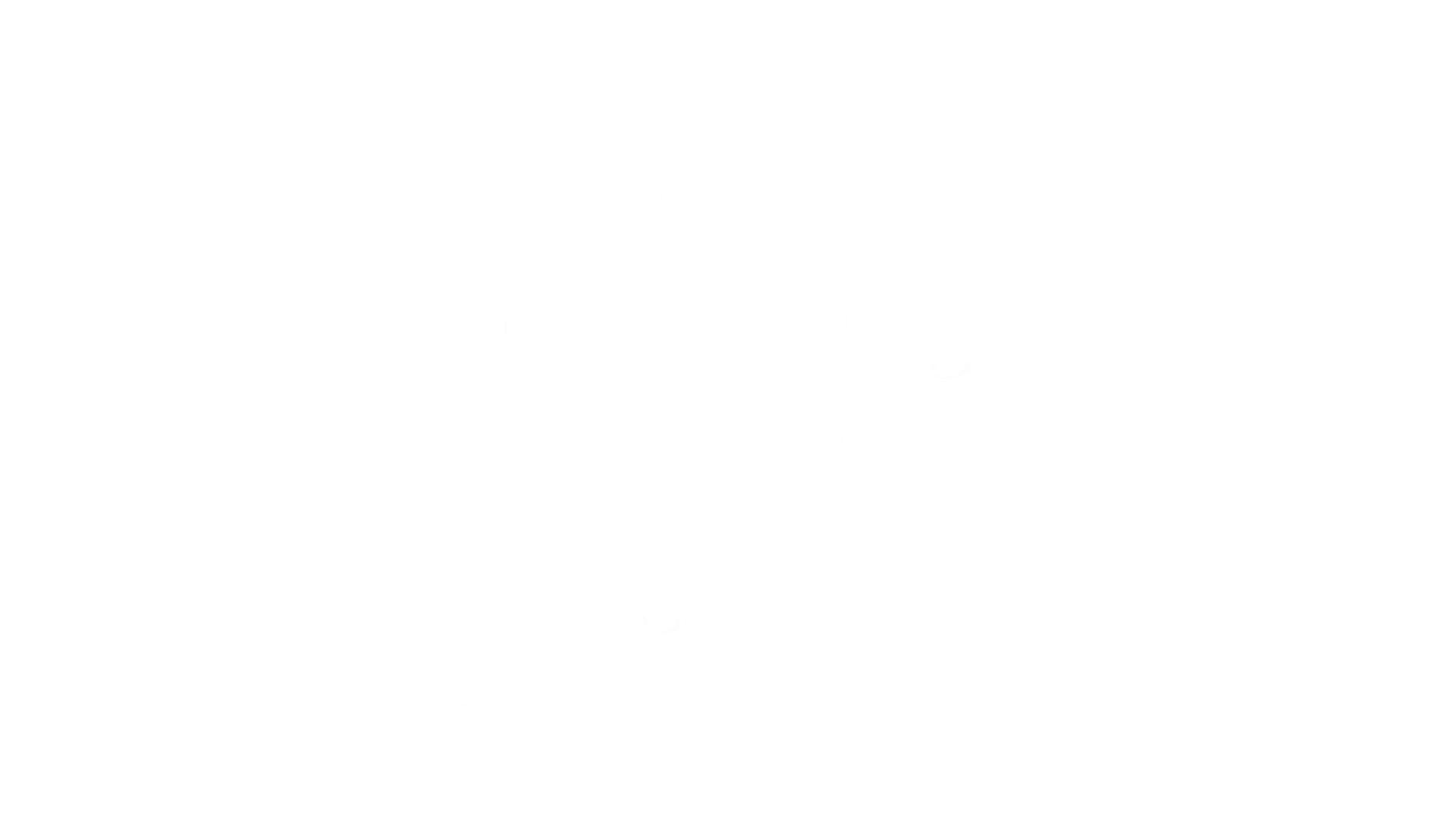
The address of each piece of data you produce is based on a cryptographic hash. That makes it effectively random, which means you don’t get to choose which neighbourhoods witness and validate your data. This prevents you from colluding with your evil friends and hiding your crime. You can try, but the person you’re trying to deceive has their own view of the DHT. They’re going to talk to the peers they trust. And when they find out nobody’s seen the data you said you published, your fraud is exposed.
Not only that, but you cryptographically sign every piece of data you produce. This means that your identity is all over the evidence.
This randomised peer witnessing, validation, and policing is what distinguishes Holochain’s rrDHT from other DHTs — it’s built for data integrity from the ground up. And that’s what makes Holochain able to perform at the speed of DHTs while offering the safety of blockchain.
Op-ed: bridging the old and the new
As I mentioned before, I’ve had a bit of a personal struggle accepting the idea of a patent on Holochain technology. I’m a bit of a starry-eyed idealist — I love free software (free-as-in-speech, although free-as-in-beer is also nice), and I love openness and sharing. Software patents feel like they’re part of the old world of enclosure, extraction, and competition.
But in the past few years of working with Holochain and Holo, I’ve come to appreciate the value of building bridges between the current world and the next. But when I reflect on it, I think that’s what we’ve been trying to do all along — working within the structures of the current world in order to birth the new. It’s unsexy, tedious, and sometimes dirty, but maybe it’s where we need to start.
There are a few reasons for this. First, if we don’t understand the rules of the game we’re stuck in, we won’t survive long enough to see the new game to maturity (this is why the troll protection). And reality is hard, messy, and inconsistent — we’re all at various stages of growth, various levels of ability to participate in new games according to our means. The current system isn’t going to just roll over and give us free room and board while we build tools for open collaboration and economics.
We also need to find ways to start unlocking and using the massive power and wealth that the current system is currently holding. We can see them as an asset, rather than a hurdle, and start ‘composting’ them into regenerative systems.
In the case of the CAL, that means we’re using the weapons of today (intellectual property law) to protect this little embryo of an idea we love so dearly. Besides being a standard open-source license, it imposes an extra restriction on those who create software with Holochain: they’re not allowed to hold your data hostage. It doesn’t mean you get to choose how it’s used (that’s an application-level concern), but it does mean you’ll never be barred from accessing it.
That feels powerful to me. It goes beyond the scope of open-source licenses to ensure freedom beyond just being able to audit and modify code. We’re embedding an ethical stance about data sovereignty into Holochain’s terms-of-use. This puts the CAL into the (sometimes controversial) territory of ‘Ethical Source’. Personally, I’m okay with that. We’ve always been explicit about our intention to support the commons, and sometimes that means asking people to consent to restrictions if they want to play this new game with us. After all, as Dr Elinor Ostrom famously demonstrated, that's what makes the commons work.