

To act in the world we must first make sense of it.
However, the world is complex, containing an amount of information exceeding the processing capacity of any individual or group. Adequate sensemaking in the context of complexity and info-abundance therefore requires the ability to process and analyse data.
We refer to this capability as data-driven sensemaking.
Yet, today the means for data-driven sensemaking are unevenly distributed. In our essay, The Politics of Data: Data Commoning as a Territory of Transition, we described how data is shaping the landscape of power, perpetuating and amplifying asymmetries. Unsurprisingly, the principal beneficiaries are large corporations and state actors with the financial and technical resources required to undertake data collection, processing and analysis at scale. As with ‘natural resources’ and ‘labour’, the dominant economic and cultural logics of today regard data as another resource to be extracted, siloed and abused in service of narrow objectives and/or for the benefit of a few.
While data alone cannot orient us, it can help to reveal new possibilities and trajectories. Yet, data only realises its potential as a coordinative aid if it is able to flow freely through our digital territories. Practices of data sharing are important — surely — but data must also be capable of transmutation; of undergoing a kind of alchemical process of reconfiguration and recombination in the midst of varying contexts. This conception regards data — or information — as a living process rather than a static object or resource. Data is made more contextually relevant when the logics and infrastructure we employ to generate, channel and transform data support these kinds of evolutionary dynamics.
Through this series of posts and the technical interventions described, we are seeking to understand and embody this conception of data as a living process, and to articulate interventions intended to help unlock data toward greater service to life. In other words, like many in the Holochain ecosystem, we are endeavouring to engage in data commoning.
Below, we will introduce the technical stack for a data commons, discussing data collection, discovery, and analysis; considering distributed computing and large language models; and proposing an algorithm library for analytic tools. We then go on to discuss the social effects of narrative and to think about how data and sensemaking could be reframed to support a generative future. Finally, in part two of this article series we will dive deeper into knowledge graphs, so don’t forget to read that article as well.
The Data Commons Stack
The capacity for commoning derives in part from maintained symmetry in power dynamics preventing data from becoming a source of extraction, enclosure, and ultimately tragedy. Consider that, the moment we click 'send' or 'save', our tweets, notes, and messages are expedited to a remote data warehouse controlled by the respective platform provider. Here our data becomes a means by which platforms increase revenue and market dominance rather than as a means for collective sensemaking. The digital spaces where we gather, lauded as the 21st century ‘town squares’ are, in truth, more like vast feudal estates. The conversations occurring within are, in many respects, the property of our digital usurpers rather than the domain of public knowledge.
Yet we remain hopeful that these power asymmetries can be mitigated — even corrected — given the right cultural and technological conditions. We’ll begin by addressing the technological dimension and speak to the cultural dimension toward the end of this post.
Layer Zero
Agent-centric, peer-to-peer (P2P) frameworks like Holochain support data commoning by providing certain assurances with respect to access, control, and provenance of the data we collectively generate. On the one hand, local-first storage affords us privacy and control with respect to our personal data whilst distributing and validating shared data among peers allows more flexible, selective means of data access. Here, data can be stewarded and evolved in a cooperative manner with reduced risk of extraction and exploitation. With these foundations, it becomes possible to support what we call 'generative information ecosystems': spaces in which information evolves toward greater complexity, relevance, and integration.
While Holochain's agent-centric architecture and data integrity mechanisms provide essential ingredients toward data sovereignty, it does not automatically grant the capability to discover and derive insights from data. Hence, an initial focus for our team at Arkology Studio is developing a suite of modules for data discovery and analysis.
For us, important sensemaking occurs in the context of our lived realities; human beings embedded in community and specific bioregions, rather than just the halls of academia and research laboratories. Hence, the hope is that the affordances of open, data-driven sensemaking tools can be matched with the orienting/decision-making capacities of grassroots organisations and communities attending to local challenges. By empowering local actors to share, discover, and draw insights from data, we may see connective tissues expand, and local solutions spread and adapt to new contexts.
The following diagram offers an initial high-level overview of a ‘data commons stack’, indicating the five functional categories or ‘layers’: collection, storage, discovery, analysis, and knowledge.
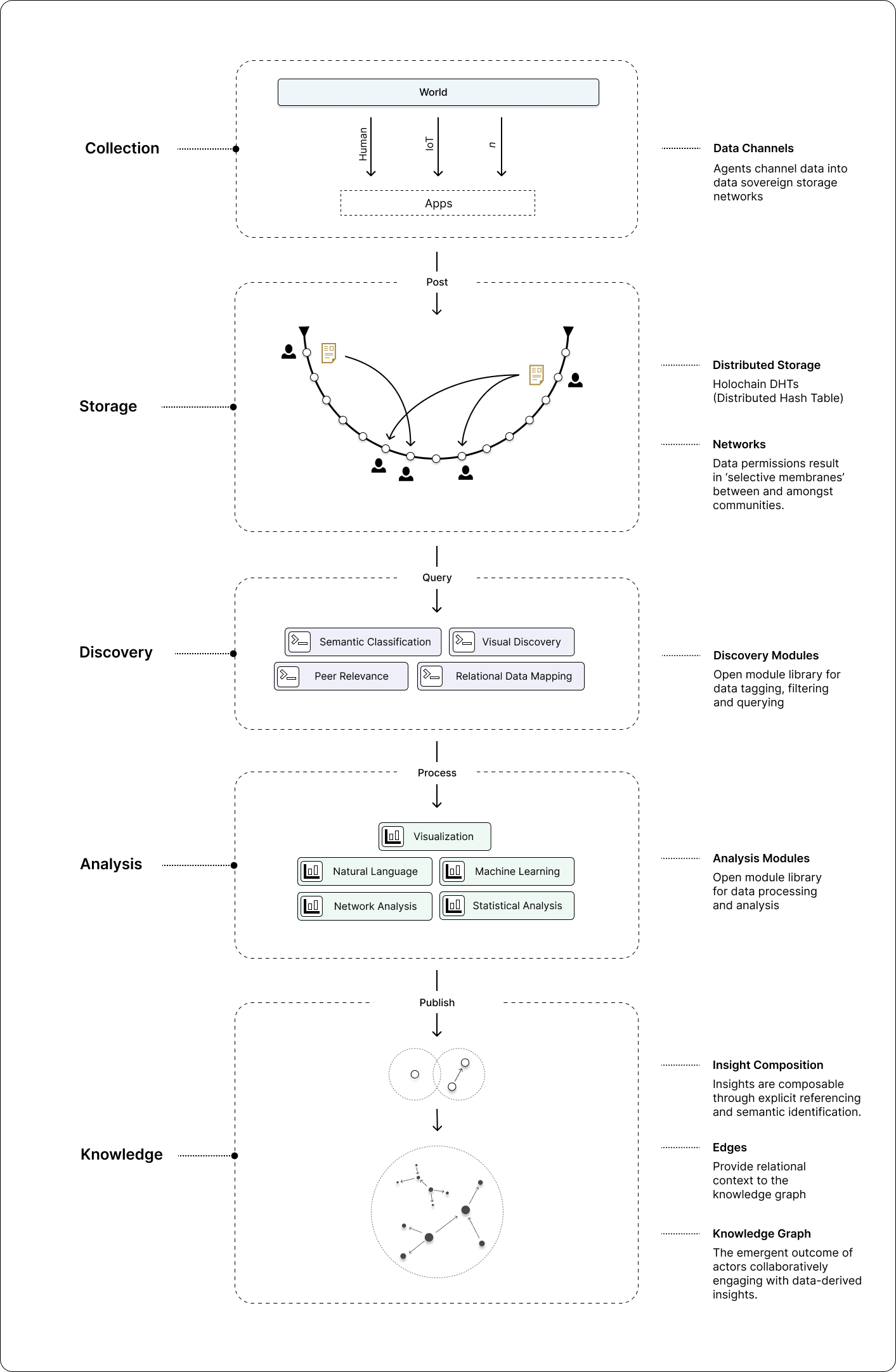
While the diagram above depicts a linear progression for illustrative simplicity, in actuality there exists a variety of feedback loops between the many subsystems. Note, for example, that published insights at the knowledge layer may themselves become data points in the data storage layer, to be included in later analyses (this unlocks, for example, interesting possibilities for narrative analysis, which we investigate in part two of this article series). Furthermore, there exists a feedback loop between our understanding of the world and our behaviour in the world. In other words, knowledge can engender change in material reality, which in turn may affect our understanding of said material reality. It is these sorts of feedback loops which reveal the complex, dynamical nature of a data commons and, if supported, enable it to adapt to evolving contexts.
Collection
Since data-driven sensemaking is impractical without a diversity of data, methods for channelling and/or exposing data from a multitude of sources is paramount. On the one hand, this involves developing standardised, consensual methods for data collection from applications, including IoT devices, traditional web apps, and other Holochain apps: what we term ‘data channels’. Data entering the ecosystem from the ‘outside’ (i.e beyond the data-sovereign membrane) is always mediated through an agent (e.g. a human or IoT device), who submits the contents along with a record containing metadata that can be recognised and validated by other agents (see Holochain’s validation rules). In other words, we record the provenance and context associated with any data point. Since other Holochain apps are already operating within their respective data-sovereign membrane, and self-host their own data, participants in those networks may reveal relevant data to the data commons ecosystem for query. As for storing all this data, Holochain already provides us with mechanisms for distributed data storage (see Holochain’s DHT), with capacity scaling linearly with the number of peers.
Discovery
With a data commons, one is presented with the challenge of effective data discovery. Since those who control the map control the territory, it is important to mitigate against monopolies on discovery mechanisms. Google’s search engine dominance engenders a kind of monoculture with respect to the very way we discover new information. Since search/discovery algorithms privilege certain data over others by design, it may be necessary to mitigate against algorithmic monopolies by encouraging a multiplicity of discovery services. Since the data commons is essentially a giant peer-to-peer (P2P) network composed of human and non-human agents, it may be useful to conceptualise these services as ‘personal agents’ who crawl the data commons on our behalf, surfacing data relevant to our needs. Imagine, for example, that you are undertaking interdisciplinary research on a controversial topic and are aware of potential biases. Here, you may be inclined to engage a search agent proficient at discovering diverse/divergent viewpoints. Furthermore, agents may operate on our behalf even when we are not actively engaged in search/discovery. For example, you may initiate an agent to notify you of regional climate events or the latest research results in cancer treatments. Since the way we acquire data is an essential step in data-driven sensemaking, it is important that we have the means to parameterize and personalise data discovery in accordance with our intentions and aspirations.
Analysis
One of the first and most exciting mechanisms for sense-making that becomes available to participants of the data commons can be conceived as similar to both SafeAnswers and secure-multiparty computation.
Essentially, ‘safe answers’ refers to the ability to perform computation on user data without revealing the raw data itself. The analyst is responsible for sending an inspectable analysis algorithm to the agent whose data is being processed for insight. This way, all computation is performed locally on the machines where the data is stored (the machine of the agent on a Holochain network). The analyst receives only the return of the algorithm and has no access to the raw data itself.
One can imagine the unlocking potential of this type of distributed computation when it comes to personal or sensitive data. This is demonstrated by an example pertaining to personal health data. On the one hand, it can be very useful to understand, say, the amount of people in a given area who are predisposed to cancer. The disposition may be informed by genetics, lifestyle, and other factors. In a traditional data relationship between an app user and a company stewarding their data, there is no assurance that the company will not use/sell their data in a compromising way, such as to an insurance firm that may increase the excesses to the user given their predisposition. By running an algorithm on the devices of the users who are being considered in the analysis, it becomes possible to undertake sensitive and important investigations without creating a honeypot of compromising data.
Algorithm Library
A library of datasets alone is necessary yet insufficient for effective sense-making. Tools are required to effectively traverse and distil the meanings and implications contained within the datasets in order for the data to affect meaningful change in the world. In order to unlock the agentic capacities of groups endeavouring to common around data towards data-driven sensemaking we are proposing a library of open-source algorithms aimed at crowd-sourcing data-science expertise in order to make data-driven sensemaking more accessible to less data-literate folk. By introducing algorithms into the data commons ecosystem, our intuition is that a data commons is not just informed by inert data points, but rather is the interaction of these data points and the actors that engage with them towards distilling an understanding of reality. In this way, it can be useful to think of this project as a praxis for data commoning, more than simply a 'data commons'.
Large Language Models
The speed of Large Language Model (LLM) development is overwhelming, with a multitude of new tools being released that are changing everything from education, to search engines, to AI assistants. Without dedicating too much of this text to this topic, it is important to indicate the possibilities for organisations and communities to develop specialised agents fine-tuned on the capacities of the data that they are commoning around. In some ways, a generative model trained on a given set of data is a codified narrative; an artificial agent acting on behalf of the semantic patterns that inform it.
Narrative Ecosystems & Cultural Evolution
The transformative potential of a given technological ecosystem is limited by the values and ontologies associated with the dominant cultural environment in which their activity is based. Hence, while we think tools that improve our capacities for sensemaking are important — especially when grounded in data-sovereign infrastructure like Holochain — they are not panaceas. Responding to the poly/metacrisis requires a transformation of the dominant culture, not merely technology.
In light of this, Arkology Studio has been collaborating with Culture Hack Labs to advance a set of tools for narrative research. For Culture Hack Labs, effective system change necessitates understanding the narrative forms and narrative ecologies that perpetuate social and ecological breakdown. Here, narratives can be understood as “interpretive social structures that frame our experience and function to bring meaning to our everyday reality, guiding our actions and decisions.” In other words, one can transform culture by intervening at the level of narratives.
The narrative, ‘data as resource’, reflects the tendency of modern, industrialised societies to regard nature — including her living creatures and material output — as something to be exploited for human benefit (or, rather, for those with the means to exploit her first). Through this framing, data is something to accumulate (‘big data’), gatekeep (e.g. academic journals), and exploit (e.g. behaviour profiling to sell ads). Contrast this narrative with ‘data in service to life’ or ‘data as living process’, which invites us to consider data and its associated processes as a fundamentally cooperative dynamic.
In recognising the power of narratives to guide cultural evolution, we have begun to explore what meaningful narrative interventions could look like in the context of a data commons. In particular, what would it mean to meaningfully shift narrative ecosystems toward more life-affirming frames without necessarily prescribing, in a top-down manner, the frames themselves? Is it conceivable, in other words, that the very insights generated within a data commons might help steer society toward a more generative future?
What’s Next?
In part two of this series, we investigate this question through a speculative discussion on the ‘knowledge’ layer of the Data Commons Stack. Specifically, we explore how to represent knowledge in a manner that is pluralistic rather than homogenising, and how we may more readily perceive the influence and evolutionary potential of the narratives that live within and amongst us. We propose a toolkit that draws from the knowledge emerging out of cooperative communities and allows the construction of agent/community-centric knowledge graphs; networks of insights built upon a shared node library and structurally arranged to represent the epistemic geometries of their ontological framing.
Our inquiry also leads us into a discussion on knowledge discovery and the risks of epistemic pluralism; in particular, how we might use open discovery patterns and quantitative measures from Integrated Information Theory to move us toward more integrative frames.
Guest Authors
This guest post, the first of two articles on data commoning, was written by Ché Coelho and Ross Eyre of Arkology Studio.
Arkology Studio (‘architecture’ + ‘ecology’) is a transdisciplinary design and software engineering studio whose mission is to support the development of commons-oriented socio-technical interventions for systems change.